How to Deploy Neural Networks on iOS
05 Feb 2023You can find the slides for this article here

Let’s assume we have a problem that requires a solution through an ML algorithm. To solve this problem, we generally need to follow these steps:
- Analyze the problem
- Collect, clean, and preprocess the data
- Build the ML algorithm that solves the problem
- Deploy the algorithm
- Monitor the results
While we often find the 3rd step exciting, with all the reading and training, we tend to forget about the crucial step of deployment. Deployment is a critical component of any ML product, and we should plan for it from the early stages of the project.
In this article, I’ll provide a general overview of deploying Neural Networks models on iOS devices. But first, why do we need to deploy the model directly on the device instead of using a server?
Server-side vs Client-side Deployment
In general, there are two solutions for deploying Neural Networks models.
The first solution is to deploy the model on a server. This can be done using frameworks such as ONNX, OpenVINO, TensorRT, etc. This approach is flexible, as we can change the model without modifying the client. Additionally, we are not restricted by the computational resources of the device.
However, this solution requires an internet connection on the client side and incurs additional costs for server maintenance.
The second solution is to deploy the model directly on the device. This approach is cost-effective and provides complete privacy. There are no scalability issues with this approach, and our server costs won’t skyrocket if our application becomes popular.
The drawback of this approach is that mobile devices have limited computational resources, and some models may be too heavy to run on the device. Furthermore, some devices may not have adequate support for neural network operations.
In conclusion, the right approach depends on the problem. In my experience, it’s best to deploy models on the device whenever possible, and only use a server when it is not possible or a more flexible solution is required.
Deployment Frameworks
When training Neural Networks models, most developers use PyTorch or TensorFlow. However, deploying these models on iOS devices requires a different approach.**
PyTorch
PyTorch offers TorchScript for deployment on iOS devices. While there are examples of apps on the PyTorch website, this approach comes with several challenges:
- TorchScript doesn’t support the Apple GPU or Apple Neural Engine.
- There is no native support for TorchScript on iOS.
- Developers need to write Objective-C or Objective-C++ wrappers for TorchScript.
If you want to explore this approach further, you can visit the PyTorch iOS deployment page for more information.
TensorFlow
TensorFlow allows for deployment on iOS devices using TensorFlow Lite. While TensorFlow provides examples of apps, it still faces similar challenges as PyTorch:
- There is no native support for TensorFlow Lite on iOS.
- Developers need to write Objective-C or Objective-C++ wrappers.
- TensorFlow Lite has support for iOS GPU, but this support is limited and available only in a nightly version. The number of supported operations is also limited.
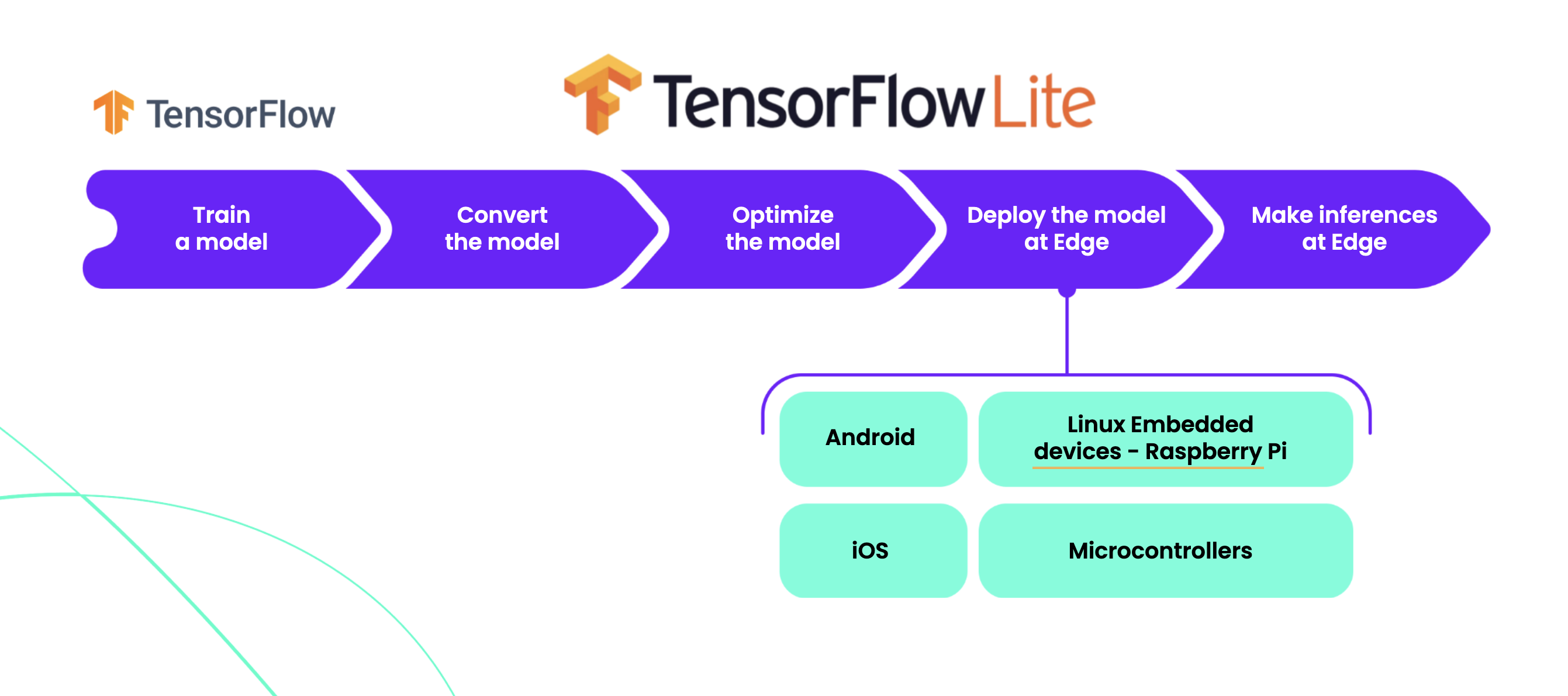
You can find more information about TensorFlow Lite deployment here and here.
CoreML
Core ML is an Apple framework that enables the integration of machine learning models into iOS apps. It is optimized for on-device performance, making use of the CPU, GPU, and Neural Engine, while keeping its memory footprint and power consumption low. To learn in-dep about Core ML, I recommend visiting this page.
When a Core ML model is added to a Xcode project, it automatically generates interfaces for the model. The framework supports image inputs and outputs and makes it easy to integrate pre- and post-processing.
So, using Core ML is the best option for integrating machine learning models into iOS apps. But during the development of these models, we typically use PyTorch or TensorFlow, not Core ML. What do we do then?
coremltools
To convert these models to the Core ML format, we use the coremltools framework. This framework can convert machine learning models from various third-party libraries, including PyTorch, TensorFlow 1 or 2, scikit-learn, and XGBoost.
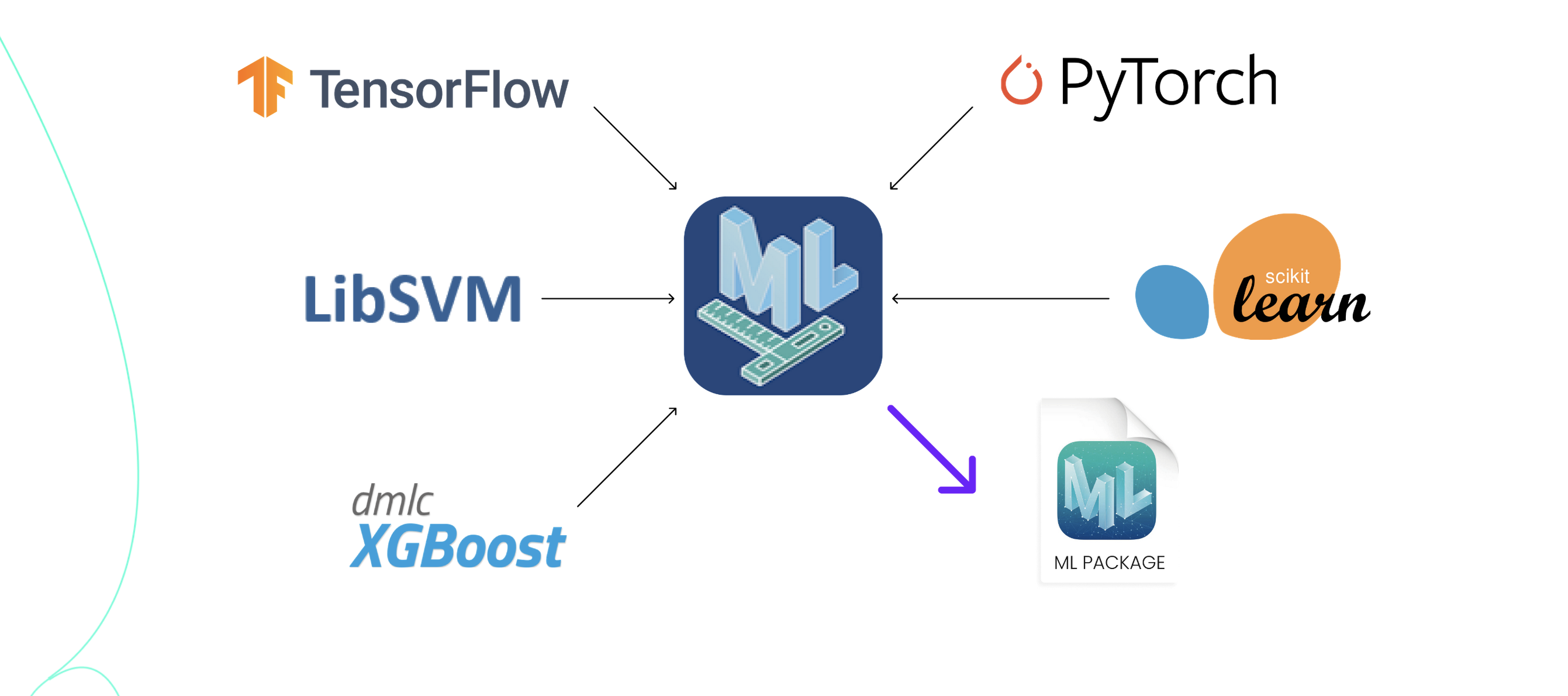
For PyTorch models, the conversion process involves first converting the model to TorchScript, and then to Core ML. There are various input and output options that can be selected, such as setting the input to an image. This makes it possible for an iOS developer to pass the image to the model directly from the camera without having to perform any additional conversions.
Quantization is another option available during the conversion process. The model can be quantized to 16 bits, or even from 1 to 8 bits. However, the lower the number of bits, the greater the risk of reduced accuracy. The extent of the loss in accuracy depends on the specific model and may vary. In general, quantizing to 16 bits should be safe and is unlikely to have a significant impact on accuracy.
While the process may seem simple, there are always details that can make things more challenging. Core ML does not support all operations, particularly newly introduced ones, which can make it difficult to convert state-of-the-art models. However, with each new version, the situation is improving, although coremltools can still lag behind.
Custom layers
You can write your own custom operations, but the official documentation suggests using this option only as a last resort. Writing a custom operation requires implementation in Swift or Objective-C and separate implementations for CPU and GPU, using different frameworks.
It is often better to use a different model or retrain your existing model with layers that are already supported by Core ML. You can also try converting your model to Core ML before training, deploying it on iOS, and comparing the results with PyTorch. If everything checks out, then you can proceed with training. For a practical example, check out this blog post.
Processing units
Modern iOS devices can run neural networks on the CPU, GPU, and Neural Engine.
The CPU and GPU are well understood, but what is the Neural Engine?
The Apple Neural Engine (ANE) is a type of Neural Processing Unit (NPU) that accelerates neural network operations, such as convolutions and matrix multiplies. Unlike a GPU, which accelerates graphics, an NPU accelerates neural network computations. You can see the ANE and GPU cores as separate areas on the A12 Bionic chip.

The ANE isn’t the only NPU on the market, as other companies have developed their own AI accelerator chips as well. A well-known NPU besides the Neural Engine is Google’s TPU.
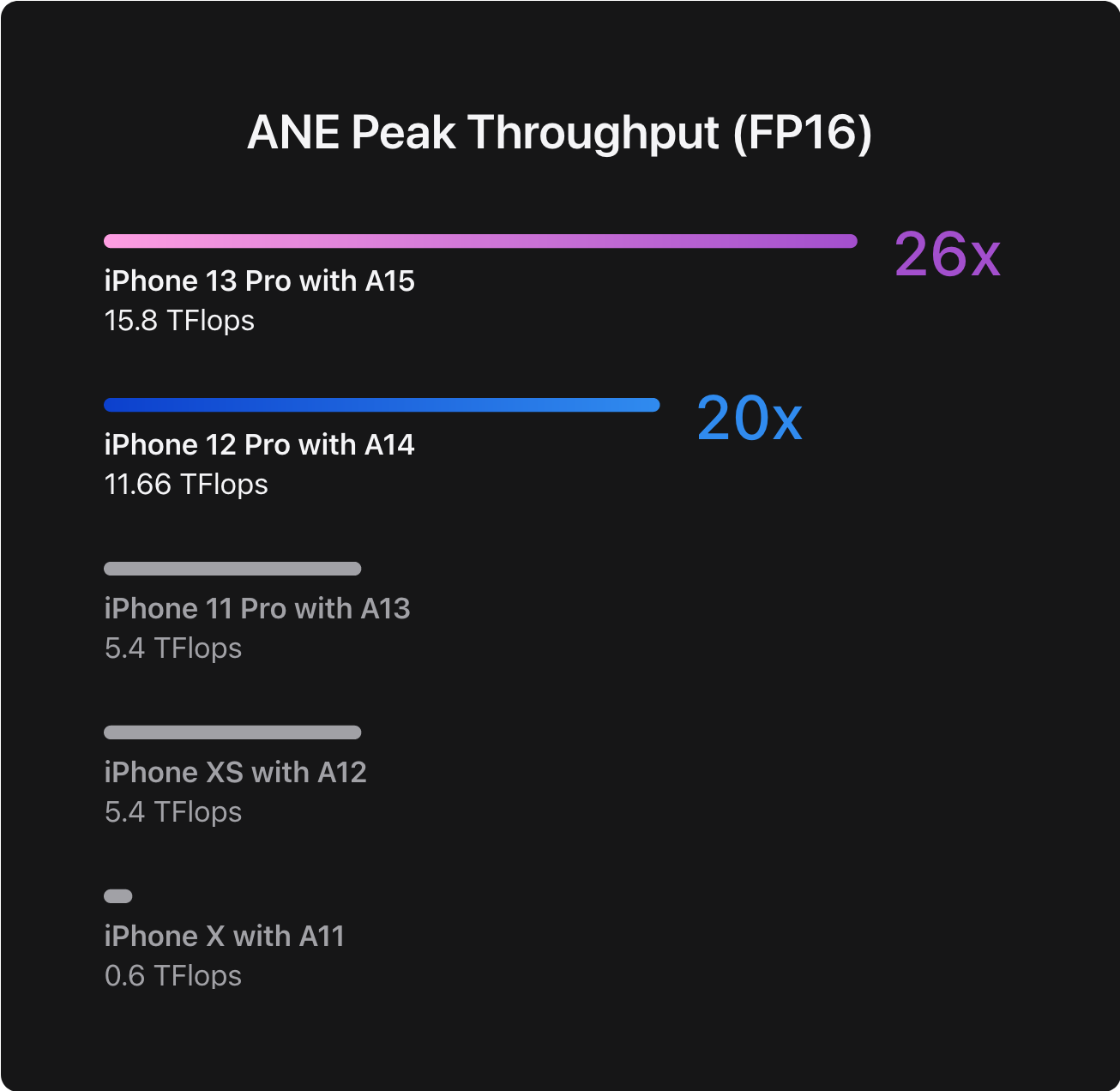
The first iteration of the Apple Neural Engine was introduced in the A11 chip, which was found in the iPhone X in 2017. It had a maximum processing power of 0.6 teraflops in half-precision and was utilized to efficiently run on-device ML features such as Face ID and Memoji.
In 2021, the fifth-generation 16-core ANE has advanced significantly, boasting 26 times more processing power, or 15.8 TFlops.
Core ML automatically selects the device (CPU, GPU, or Neural Engine) on which your model will run. However, it allows you to limit the device selection by specifying the following options:
- CPU only
- CPU and GPU
- All (Neural Engine, CPU, and GPU)
For a comparison of performance for neural networks on CPU, GPU, and ANE, see this blog post. If you want to dive into the technical details of the Apple Neural Engine, visit this GitHub repository.
Conclusion
In conclusion, deploying a neural network on iOS can be a challenge, but with the right approach and tools, it can be done successfully. Start by testing the conversion to CoreML, as many state-of-the-art networks may not be convertible. Consider using an older algorithm that solves your problem and converts to CoreML or replacing non-convertible operations with convertible ones.
In most cases, a few percentage differences in the target metric may not be worth spending weeks trying to solve conversion problems. When you have found an architecture that supports CoreML, you can then train it for your specific task.
Quantizing your model to half-precision and changing input and output nodes to ImageType instead of FloatType can also improve inference speed and save time for iOS developers. If speed is a concern, ensure that your model uses the GPU or ANE. If it doesn’t, use XCode utilities for debugging.